2025年1月,人工智能伦理论坛在哈尔滨顺利举办。中国软件评测中心(工业和信息化部软件与集成电路促进中心)与上海人工智能实验室联合发布了《医疗健康领域大模型发展分析报告(2024)》(以下简称《报告》)。
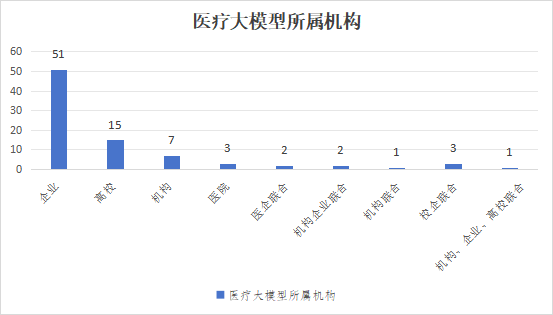
《报告》对我国85家企业和机构发布的医疗健康大模型,从发展现状、场景落地及医疗健康大模型应用能力开展测评。从研发主体来看,研发主体趋向多元,但以企业为主,占据了医疗健康领域大模型研发的主导地位,高校和科研机构为辅,医疗机构次之,研发合作模式多样化,包括医企、校企等多种模式。
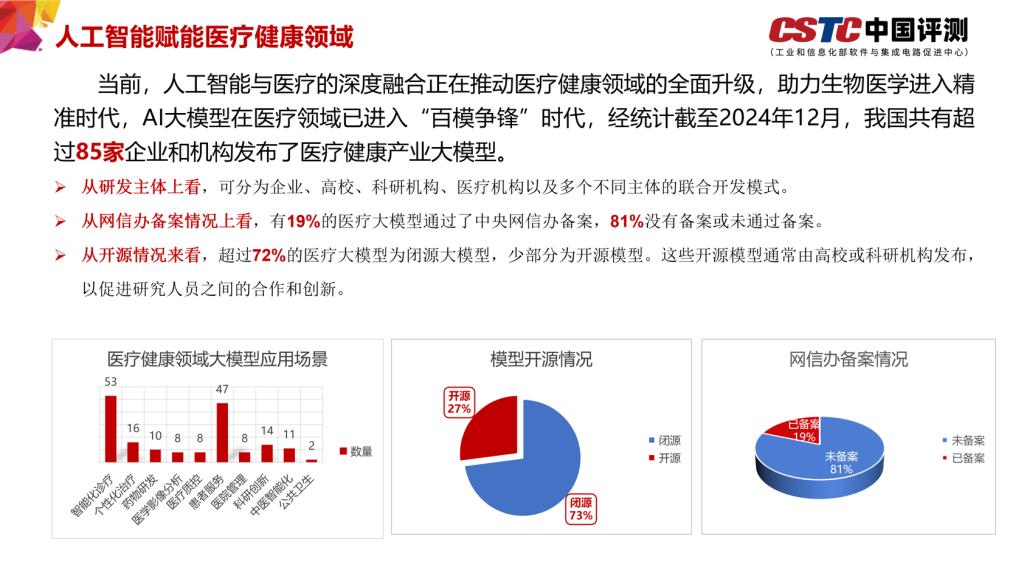
从场景应用来看,目前医疗健康大模型已落地了智能化诊疗、个性化治疗、药物研发、医学影像分析、医疗质控、患者服务、医院管理、教学科研、中医智能化、公共卫生等多个应用场景,切实提升了人们获得医疗服务的便捷性。如在智能化诊疗应用场景,灵医大模型、京医千询等53个大模型通过分析海量医疗数据,能够辅助医生进行更准确的诊断。在个性化治疗应用场景,左医GPT、达尔文大模型等16个大模型可对患者进行精准画像,制定个性化治疗方案,帮助实现千人千面的患者管理策略。在药物研发场景,全原子生物分子模型OpenComplex 2、医渡大模型、“达尔文”等10家大模型,应用于早期的药物筛选、药物优化,药物的临床试验和后期的上市监控。
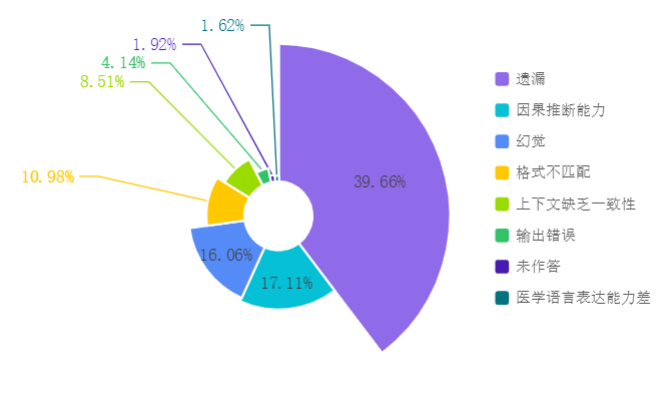
从MedBench在复杂医学推理、医学语言生成、医学知识问答、医学安全与伦理及医学语言理解五个维度的评测结果来看,遗漏(39.66%)、因果推断(17.11%)及幻觉(16.06%)是导致大模型结果数据错误的主要原因。其中,在医学知识问答任务中,高达44.40% 的错题归因于信息遗漏,在医学语言理解任务方面主要归因于遗漏信息(34.30%)以及因果推断能力欠缺(22.53%),在医学语言生成任务则主要归因于幻觉(63.99%)。
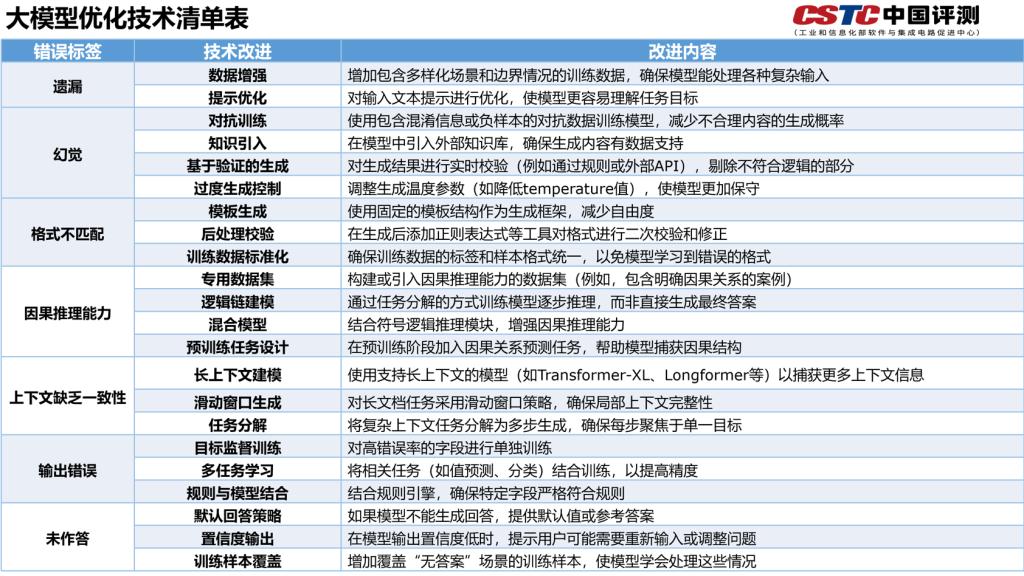
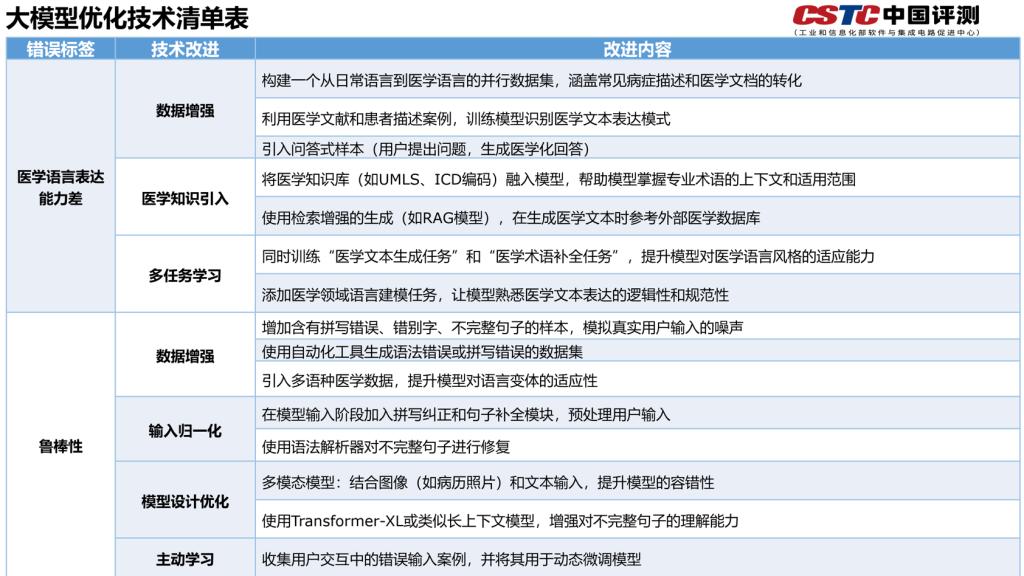
未来医疗大模型应在技术创新、高质量数据构建、伦理与合规及完善评估评测体系等多方面协同发力,下一步中国软件评测中心人工智能研究测评事业部联合上海人工智能实验室将与业界共同开展医疗领域大模型的应用评价、安全可靠性等研究。
